Python 源码阅读 - tuple
还差一篇……写完写简历>_<#
示例
>>> a = ()
>>> b = ()
>>> id(a) == id(b)
True
>>> a = (1, )
>>> b = (1, )
>>> id(a) == id(b)
False
源码位置 Include/tupleobject.h | Objects/tupleobject.c
结构
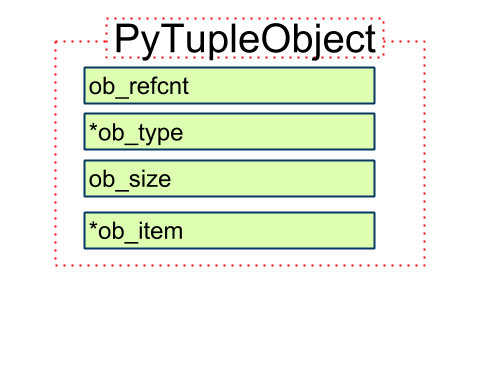
定义
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
说明
1. PyObject_VAR_HEAD
PyTupleObject在底层是个变长对象(需要存储列表元素个数).
虽然, 在python中, tuple是不可变对象
2. PyObject *ob_item[1];
指向存储元素的数组
3.
结构
构造方法
PyAPI_FUNC(PyObject *) PyTuple_New(Py_ssize_t size);
构造
看下构造方法定义
PyObject *
PyTuple_New(register Py_ssize_t size)
{
register PyTupleObject *op;
Py_ssize_t i;
// 大小为负数, return
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
// 如果大小=0, 空元组, 直接取free_list第一个返回
#if PyTuple_MAXSAVESIZE > 0
if (size == 0 && free_list[0]) {
op = free_list[0];
Py_INCREF(op);
#ifdef COUNT_ALLOCS
tuple_zero_allocs++;
#endif
return (PyObject *) op;
}
// 如果free_list可分配, 从free_list取一个
if (size < PyTuple_MAXSAVESIZE && (op = free_list[size]) != NULL) {
// 上面 op = free_list[size] 取得单链表头
// free_list指向单链表下一个元素, 对应位置阈值--
free_list[size] = (PyTupleObject *) op->ob_item[0];
numfree[size]--;
#ifdef COUNT_ALLOCS
fast_tuple_allocs++;
#endif
// 初始化 ob_size和ob_type
/* Inline PyObject_InitVar */
#ifdef Py_TRACE_REFS
Py_SIZE(op) = size;
Py_TYPE(op) = &PyTuple_Type;
#endif
_Py_NewReference((PyObject *)op);
}
else
#endif // free_list不可用
{
// 计算空间
Py_ssize_t nbytes = size * sizeof(PyObject *);
/* Check for overflow */
if (nbytes / sizeof(PyObject *) != (size_t)size ||
(nbytes > PY_SSIZE_T_MAX - sizeof(PyTupleObject) - sizeof(PyObject *)))
{
return PyErr_NoMemory();
}
// 分配内存
op = PyObject_GC_NewVar(PyTupleObject, &PyTuple_Type, size);
if (op == NULL)
return NULL;
}
// 初始化ob_item每个元素
for (i=0; i < size; i++)
op->ob_item[i] = NULL;
// 第一次分配空数组, 将其放入free_list第一个位置
#if PyTuple_MAXSAVESIZE > 0
if (size == 0) {
free_list[0] = op;
++numfree[0];
Py_INCREF(op); /* extra INCREF so that this is never freed */
}
#endif
#ifdef SHOW_TRACK_COUNT
count_tracked++;
#endif
_PyObject_GC_TRACK(op);
// 返回
return (PyObject *) op;
}
简化步骤
1. 如果size=0, 从free_list[0]取, 直接返回
2. 否则, 确认free_list[size], 是否可用, 可用获取
3. 否则, 从内存分配新的空间
4. 初始化, 返回
回收
定义
static void
tupledealloc(register PyTupleObject *op)
{
register Py_ssize_t i;
// 获取元素个数
register Py_ssize_t len = Py_SIZE(op);
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (len > 0) {
i = len;
// 遍历, 析构每个元素
while (--i >= 0)
Py_XDECREF(op->ob_item[i]);
// 与对象缓冲池相关
#if PyTuple_MAXSAVESIZE > 0
if (len < PyTuple_MAXSAVESIZE &&
numfree[len] < PyTuple_MAXFREELIST &&
Py_TYPE(op) == &PyTuple_Type)
{
op->ob_item[0] = (PyObject *) free_list[len];
numfree[len]++;
free_list[len] = op;
goto done; /* return */
}
#endif
}
// 调用回收
Py_TYPE(op)->tp_free((PyObject *)op);
done:
Py_TRASHCAN_SAFE_END(op)
}
简化流程
1. 回收ob_item每个元素
2. 如果符合条件, 放入到free_list
3. 否则, 回收
tuple对象缓冲池
定义
/* Speed optimization to avoid frequent malloc/free of small tuples */
#ifndef PyTuple_MAXSAVESIZE
#define PyTuple_MAXSAVESIZE 20
#endif
#ifndef PyTuple_MAXFREELIST
#define PyTuple_MAXFREELIST 2000
#endif
#if PyTuple_MAXSAVESIZE > 0
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
static int numfree[PyTuple_MAXSAVESIZE];
#endif
结论
1. 作用: 优化小tuple的mall/free
2. PyTuple_MAXSAVESIZE = 20
会被缓存的tuple长度阈值, 20, 长度<20的, 才会走对象缓冲池逻辑
3. PyTuple_MAXFREELIST 2000
每种size的tuple最多会被缓存2000个
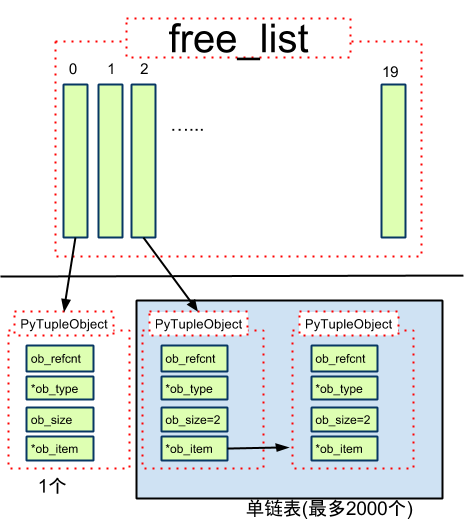
4. PyTupleObject *free_list[PyTuple_MAXSAVESIZE]
free_list, 指针数组, 每个位置, 存储了指向一个单链表头的地址
5. numfree[PyTuple_MAXSAVESIZE]
numfree, 一个计数数组, 存储free_list对应位置的单链表长度
6. free_list[0], 指向空数组, 有且仅有一个
free_list的结构
回头看回收跟对象缓冲池相关的逻辑
条件:
if (len < PyTuple_MAXSAVESIZE && // len < 20
numfree[len] < PyTuple_MAXFREELIST && // numfree[len] < 2000
Py_TYPE(op) == &PyTuple_Type) // 是tuple类型
操作
op->ob_item[0] = (PyObject *) free_list[len]; //ob_item指向free_list[len] 单链表头
numfree[len]++; // len位置计数+1
free_list[len] = op; // op变成单链表的头
goto done; /* return */
即过程
1. 如果size=0, 直接从free_list[0]取
2. 如果size!=0, 判断size<20?
3.1 size < 20, 从free_list对应size位置的单链表, 取头部第一个位置
3.2 size < 20, free_list对应size位置还没有可用对象的话, 走内存分配逻辑
4 size > 20 走内存分配逻辑
------------------
回收时
如果size<20, 且free_list对应位置单链表长度没达到上限(2000), 将对象放入到单链表头
注意
1. 回收时, ob_item都会被回收, 只是本身对象缓存下来
2. 这里free_list, 复用ob_item作为链表指针, 指向下一个位置(通用整数对象池也是复用指针的方式, 不过用的是ob_type)
changelog
2014-08-10 first version