Python 源码阅读 - dict
基本类型实现的最后一篇, 先告一段落, 专心找工作去……搞定工作后再开始扫后面的
源码位置 Include/dictobject.h | Objects/dictobject.c
PyDictObject的存储策略
1. 使用散列表进行存储
2. 使用开放定址法处理冲突
2.1 插入, 发生冲突, 通过二次探测算法, 寻找下一个位置, 直到找到可用位置, 放入(形成一条冲突探测链)
2.2 查找, 需要遍历冲突探测链
2.3 删除, 如果对象在探测链上, 不能直接删除, 否则会破坏整个结构(所以不是真的删)
关于 hash表的 wiki
基本键值PyDictEntry
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
说明
1. PyDictEntry 用于存储键值对信息
2. Py_ssize_t me_hash
存储了me_key计算得到的hash值, 不重复计算
结构
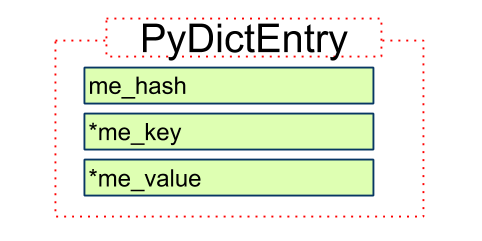
PyDictEntry的三个状态(图片引自-Python源码剖析)
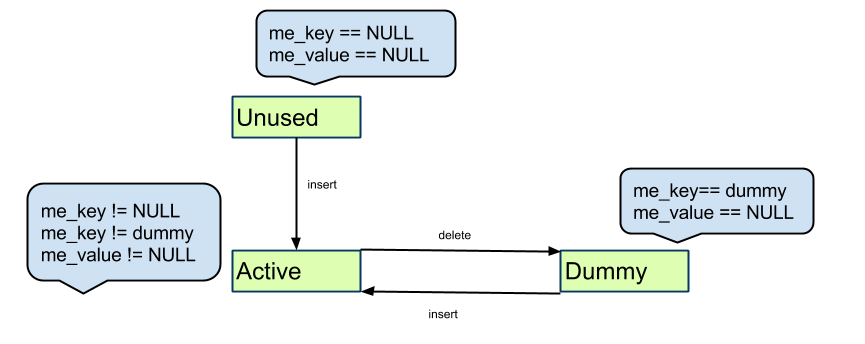
PyDictObject定义
定义
typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};
说明
1. PyObject_HEAD
反而声明为定长对象, 因为ob_size在这里用不上, 使用ma_fill和ma_used计数
2. Py_ssize_t ma_fill;
Py_ssize_t ma_used;
ma_fill = # Active + # Dummy
ma_used = # Active
3. Py_ssize_t ma_mask;
散列表entry容量 = ma_mask + 1, 初始值ma_mask = PyDict_MINSIZE - 1 = 7
ma_mask + 1 = # Unused + # Active + # Dummy
4. PyDictEntry *ma_table;
指向散列表内存, 如果是小的dict(entry数量<=8). 指向ma_smalltable数组
5. ma_lookup
搜索函数
6. PyDictEntry ma_smalltable[PyDict_MINSIZE];
小dict, 大小8, 小于8个键值对的字典会直接存放在这里, 超出后再从内存分配空间
结构

结论
1. PyDictObject在生命周期内, 需要维护ma_fill/ma_used/ma_mask 三个计数值
2. 初始化创建是ma_smalltable, 超过大小后, 会使用外部分配的空间
构造过程
定义
PyObject *
PyDict_New(void)
{
register PyDictObject *mp;
// 初始化dummy
if (dummy == NULL) {
dummy = PyString_FromString("<dummy key>");
if (dummy == NULL)
return NULL;
// 暂时忽略
#ifdef SHOW_CONVERSION_COUNTS
Py_AtExit(show_counts);
#endif
#ifdef SHOW_ALLOC_COUNT
Py_AtExit(show_alloc);
#endif
#ifdef SHOW_TRACK_COUNT
Py_AtExit(show_track);
#endif
}
// 如果PyDictObject缓冲池可用
if (numfree) {
// 取缓冲池最后一个可用对象
mp = free_list[--numfree];
assert (mp != NULL);
assert (Py_TYPE(mp) == &PyDict_Type);
_Py_NewReference((PyObject *)mp);
// 初始化
if (mp->ma_fill) {
// 1. 清空 ma_smalltable
// 2. ma_used = ma_fill = 0
// 3. ma_table -> ma_smalltable
// 4. ma_mask = PyDict_MINSIZE - 1 = 7
EMPTY_TO_MINSIZE(mp);
} else {
// 1. ma_table -> ma_smalltable
// 2. ma_mask = PyDict_MINSIZE - 1 = 7
INIT_NONZERO_DICT_SLOTS(mp);
}
assert (mp->ma_used == 0);
assert (mp->ma_table == mp->ma_smalltable);
assert (mp->ma_mask == PyDict_MINSIZE - 1);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else {
// 创建一个
mp = PyObject_GC_New(PyDictObject, &PyDict_Type);
if (mp == NULL)
return NULL;
// 初始化 1/2/3/4
EMPTY_TO_MINSIZE(mp);
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
// 搜索方法, 关注这个
mp->ma_lookup = lookdict_string;
#ifdef SHOW_TRACK_COUNT
count_untracked++;
#endif
#ifdef SHOW_CONVERSION_COUNTS
++created;
#endif
// 返回
return (PyObject *)mp;
}
简化步骤
1. 如果PyDictObject对象缓冲池有, 从里面直接取, 初始化
2. 否则, 创建一个, 初始化
3. 关联搜索方法lookdict_string
4. 返回
结论
1. 关注对象缓冲池
2. 关注lookdict_string
销毁过程
方法定义
static void
dict_dealloc(register PyDictObject *mp)
{
register PyDictEntry *ep;
Py_ssize_t fill = mp->ma_fill;
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
// 遍历销毁ma_table中元素 (ma_table可能指向small_table 或 外部)
for (ep = mp->ma_table; fill > 0; ep++) {
if (ep->me_key) {
--fill;
Py_DECREF(ep->me_key);
Py_XDECREF(ep->me_value);
}
}
// 如果指向外部, 销毁整个(上面一步只销毁内部元素)
if (mp->ma_table != mp->ma_smalltable)
PyMem_DEL(mp->ma_table);
// 如果对象缓冲池未满且是PyDict_Type, 放入
if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type)
free_list[numfree++] = mp;
else
// 否则回收
Py_TYPE(mp)->tp_free((PyObject *)mp);
Py_TRASHCAN_SAFE_END(mp)
}
PyDictObject对象缓冲池
定义
#ifndef PyDict_MAXFREELIST
#define PyDict_MAXFREELIST 80
#endif
static PyDictObject *free_list[PyDict_MAXFREELIST];
static int numfree = 0;
对象缓冲池的结构(跟PyListObject对象缓冲池结构基本一样)
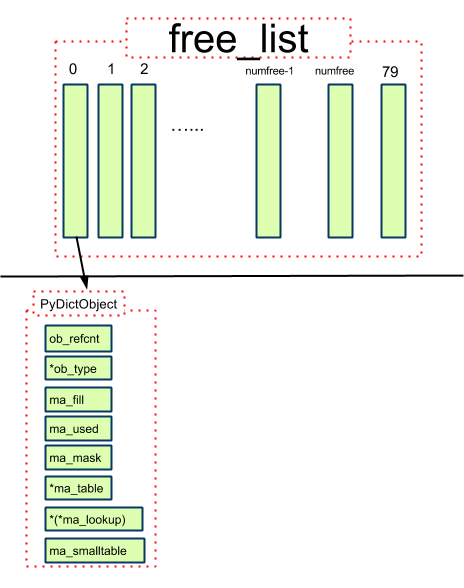
结论
1. 最多会缓存80个对象
2. 只缓存 PyDictObject 本身, 其PyDictEntry全部会被回收
3. 缓存对象进去, 旧有的值没有变化, 取出来用的时候初始化时才改变
Dict 操作
查找/插入/resize/删除, 下个版本补
changelog
2014-08-11 first version