简单搜索系统组成总结
最近在进行离职前交接工作了, 对之前做的一些东西也大概进行了下简单总结.
今天整理了下, 搜索系统组成简要描述, 一些思想, 不涉及太多具体实现.
这套系统从开始设计到最终完成, 前前后后花了3个月的样子(计算所有时间投入), 也算是做得感觉比较完善的一套系统.
上线接近一年, 支持快玩游戏搜索业务(快玩盒子/快玩网站/移动端等), 系统每天百万级的搜索(峰值在250w左右, 应用层两台机器负载均衡, 单机核心层, 单机引擎), 很遗憾, 由于业务所限, 一直没有看到这套系统能支持的量上限, 即使在峰值, 核心层qps大概也才50左右, 预计搜索量到千万级应该没什么压力, 当然, 优化的余地还很多.
外面正在狂风骤雨, 开始吧
目标
当系统数据达到一定量时, 搜索就成为了除类目以外的第二大入口.
- 更好的搜索结果(指标: 召回率, 转化率, 排序效果)
- 更好的用户体验(下拉提示点击率,相关搜索准确率等)
搜索流程
-
用户在输入框输入关键词, 此时输入框会下拉提示一些词, 用户可以选择进行搜索
-
用户点击, 进行搜索, 前端调用搜索接口
-
应用层
3.1 请求关键词改写, 获得改写后词 3.2 查询缓存是否存在, 存在直接返回缓存内容. 此时, 会记录搜索日志 3.3 不存在缓存, 调用解析输入, 调用核心层接口 -
核心层, 调用引擎接口, 获取搜索结果, 并整合信息, 返回应用层
-
应用层, 获取结果, 此时根据需要, 可能调用相关搜索和热门词服务, 获取必要信息, 最终进行页面渲染, 记录日志, 返回给客户端
系统结构图
实现: java(solr)只需配置 + python(所有服务) + golang(suggestion)
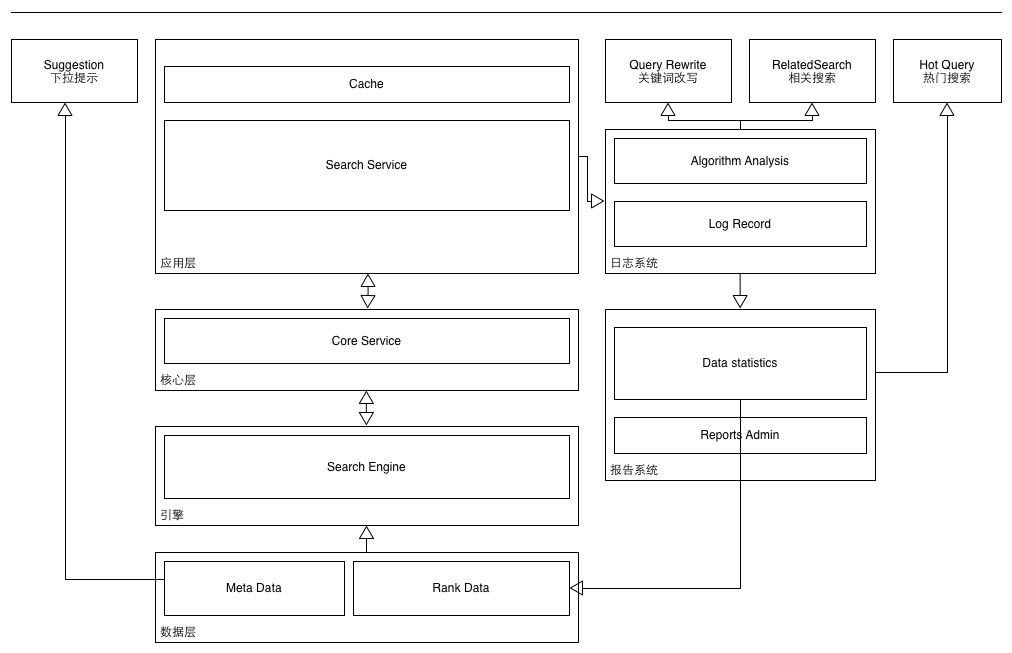
系统组成(简单描述)
对外服务
搜索整体系统,对外提供服务包括
- 基本搜索服务 用户输入query, 系统返回筛选并且排序后的结果, 在前端进行展现
- 下拉提示服务 用户在输入框输入query时, 下拉框根据输入提示搜索关键词, google/baidu的搜索框
- 相关搜索服务 在搜索结果页,根据用户所在的系统(客户端/移动端/网站等)以及关键词,提示搜索query相关的搜索
- 热门搜索 在某些业务中,或者前端,展示热门搜索关键词
- 关键词改写 对用户输入关键词进行改写, 以获取更好的搜索结果, 或者进行关键词纠错, 转换
缓存
缓存在整个搜索系统中起到很关键的作用, 各个服务都需要使用缓存进行优化
系统使用memcached/redis分别进行处理. 整个搜索中用得最多的是下拉提示suggestion, 用户输入关键词整个过程中存在变动都会发起一次请求.
业务(应用层+核心层)
核心层, 提供单一职责, 灵活且性能足够的接口
应用层, 根据不同系统的业务需求进行编写, 调用核心层接口获取数据, 整合搜索结果, 并进行展示渲染
元信息(数据元信息+排行信息等)
业务本身的核心数据, 包含元信息, 元信息中只有少部分需要导入引擎, 建立索引 or 存储, 元信息中还可能包含排序相关的信息, 例如评分等
排行信息, 主要来自后端统计系统
引擎
对元信息, 进行分析并处理, 建立索引, 存储内容
并提供搜索, 可以决定排序规则
日志系统
负责记录各个服务的日志, 用于统计以及其他服务的数据挖掘
可以记录每次搜索的时间,用户,关键词,改写词,是否有结果,结果信息, 翻页信息等等
算法模块
对记录日志进行分析, 使用算法生成其他服务需要的数据
报告系统
对日志进行统计, 计算搜索pv/uv, 无结果率, 搜索关键词排行, 下拉提示点击率等等
用于关键性指标的统计, 方便针对性优化
接下去, 分块简要说明下
搜索服务-数据层
数据存储跟各自业务有关系, 信息录入渠道主要是运营录入或者抓取导入等, 存储使用mysql/postgresql等数据库
rank data 主要是由日志系统统计出一些根据涉及排序相关的数据, 例如用户点击次数, 玩次, 评分等等, 会直接影响到结果排序
注意, 由于这些数据都会存在变更, 所以, 需要存储update_time, 用于引擎增量建立索引.
搜索服务-引擎
实现上, 使用的是开源的 apache solr, 版本4.5, 刚才看了下最新版到了4.8了.
曾经一度想自己去实现, 结果发现复杂化了, 系统设计中, 切忌把实现问题的手段当做问题本身去处理.
还有很多同类引擎, 可以去对比下.
选中solr的原因: 简单
- 输入, 足够简单的数据提供方式, 通过配置文件定义数据库及sql等信息, 就可以建立元数据到引擎数据的关系, 且有接口可以方便地进行全量/增量更新
- 配置简单, 可以配置索引处理方式, 例如中文分词,拼音搜索等, 可以配置不同接口的排序, 可以配置缓存等. ps: 拼音搜索可以使用
EdgeNGram索引处理实现. - 输出, 足够强大的查询接口
对于引擎, 很重要一块是搜索结果排序, solr 可以很方便地支持自定义排序, 可以依赖于输入数据中的排序字段, 进行公式计算, 得到最终的加权和, 用于决定排序. 这里的公式需要针对业务中影响排序的因素进行分析, 然后不断调整因素的权重, 得到最终的排序效果.
如果要进行一些其他处理, 可以在应用层或核心层进行额外处理.
下拉提示服务
前后做了两个版本, 一个版本基于分词-统计-cache实现的, 后面一个版本基于 trie树-cache实现.
元信息直接导出, 以游戏为例, 游戏名+图标+类型+玩次等信息
主要是针对游戏名进行处理:(原词+拼音+拼音首字母)
植物大战僵尸 -> [植物大战僵尸, zhiwudazhanjiangshi, zwdzjs]
然后, 在内存中建立前缀树. 这里使用的是double-arry-trie实现
double-array-trie文章: What is Trie | An Implementation of Double-Array Trie
用户输入query, 没发生一次变化, 发送请求到下拉提示服务, 首先会去命中缓存, 未命中, 进入trie树搜索前缀, 获取此前缀所有后缀, 即获取提示关键词集合, 排序获取权重最高的进行返回(是这个流程, 但实际上没那么简单, 要考虑性能).
如果不开缓存,实时计算的话,对cpu占用率非常高,每次都要搜索trie树,所以开启了memcached外部缓存.
开源了一份, 但并不是线上的实现, 而是优化版本, 但是一直没有机会上到线上看下效果, 有兴趣可以看下 suggestion
相关搜索服务
目前做得比较简单, 使用同一个用户的搜索关键词链进行分析, 处理成
[ 搜索关键词-后继搜索关键词], 并进行统计, 最终获取统计结果.
这个服务一直没有进行优化, 导致相关搜索的结果并不好, 存在很多bad case(推荐重复的内容/单字符推荐等).
可以基于算法进行重构.
关键词改写
关键词改写, 主要分成两类, 一类是输入关键字错误导致无结果(错别字/缺字/多字等), 另一类是输入关键字是业务上某些名称的别名, 系统内没有, 需要转换.
通过改写, 可以实现纠错以及转换的目的, 使用户能正确获取结果
关于纠错, 目前处理方式, 用户搜索关键词链, 处理成 [无结果词 - 有结果词], 另外还有用户下拉提示点击 [无结果输入词 - 有结果点击词], 然后进行统计, 根据一系列规则进行筛选, 获取改写列表.(目前是基于规则的, 优化空间还很大)
关于业务上的改写, 需要提供入口, 提供给运营人员针对一些术语进行改写, 例如[gta -> 侠盗猎车手]
这个服务比较简单粗暴, 计算完成后直接将键值对刷入缓存, 对外提供服务.
关键词改写需要进行持续的优化, 定期获取新的日志进行批量处理, 加入列表. 优化余地很大, 可以有效降低无结果率.
统计
主要对每日的搜索日志进行统计, 得到两部分信息:
- 报表数据: 不同平台不同渠道的每日pv/uv, 无结果率, 下拉提示点击率等
- 排行数据: 不同纬度下搜索排行, 用于反向作用于搜索引擎排序
一些坑
- 系统使用的
memcached集群作为缓存, 遇到一些坑, 例如key最大长度250,key不能包含空格和控制字符, 存储数据最大1M. 即, 默认对用户的输入不信任(看日志才知道有多少奇葩的搜索query). 切成redis或许会好一些. - 关于备份. 由于业务初期流量一直不大, 所以除了应用层使用
nginx做负载均衡外, 核心层和solr都使用单机实例. 带来的问题是, 虽然整体负载不高, 但是没有备份, 出现过一次solr引擎挂到导致搜索整体失效30分钟的故障, 后面对每个单机服务都进行了服务备份, 失效启用. - 需要对整体系统进行监控, 使用
sentry和statsd, 可以实时监测到流量变化以及程序错误. - 日志很重要, 要针对自己需要了解的指标以及需要统计分析的字段, 设计尽可能完整的日志记录.
一些感想
需要确认整体目标, 然后建立关键性指标, 实现基础方案, 上线, 并持续地关注数据, 分析日志以及bad case, 然后进行优化, 观察指标变化. 记得系统最初的召回率84%, 后来一步步提升到了92%. 这是一个长期的, 不断优化的过程.
很多东西, 都需要自己一步步去摸索和尝试.
当然, 这只是一个小型的搜索系统, 其中每一个模块都可以针对性地扩展和优化, 使用更好的算法, 达到更好的效果.
It’s simple, but it works, that’s enough:)
系统总是跟随业务逐渐成长变化的, 很可惜, 业务夭折, 这个系统可能失去了在这里继续进化的可能.
希望提供一些可供大家借鉴的方法. That’s all.
先这样吧
wklken
2014-06-09 于深圳